Bridging the Gap: Hybrid Kubernetes Clusters with Remote Control Planes
As organizations continue to navigate the complex landscape of container orchestration, Kubernetes stands out as a leading solution for deploying, managing, and scaling containerized applications.
However, on-premises infrastructures with limited availability zones face unique challenges, particularly when it comes to ensuring the resilience of the etcd cluster – a critical component for maintaining the state of the Kubernetes cluster.


Challenges of Limited Availability Zones
Etcd is based on the Raft algorithm. Establishing a robust Raft consensus for the etcd cluster becomes a formidable task in on-premises environments, usually with only two availability zones.
To learn more about the internals of Raft, we suggest you read this great article by Daniele Polencic (LearnK8s)
With that said, a Kubernetes Control Plane requires an odd number of instances to ensure a clear majority in decision-making. With an odd number, such as 3, 5, or 7 instances, the system can establish a majority more effectively.
This design choice prevents tie-breaker scenarios and allows the Raft algorithm to achieve consensus more robustly. In the event of a network partition or node failure, an odd number of instances ensures that a majority can still be reached, maintaining the integrity and fault tolerance of the consensus algorithm.
When etcd is split across only two availability zones, it introduces a significant risk of failure due to the nature of its fault tolerance mechanism. In a two-zone configuration, if one zone fails, there's a probability that the operational majority of etcd instances is in the failed zone, leading to the entire Kubernetes cluster becoming inoperative.
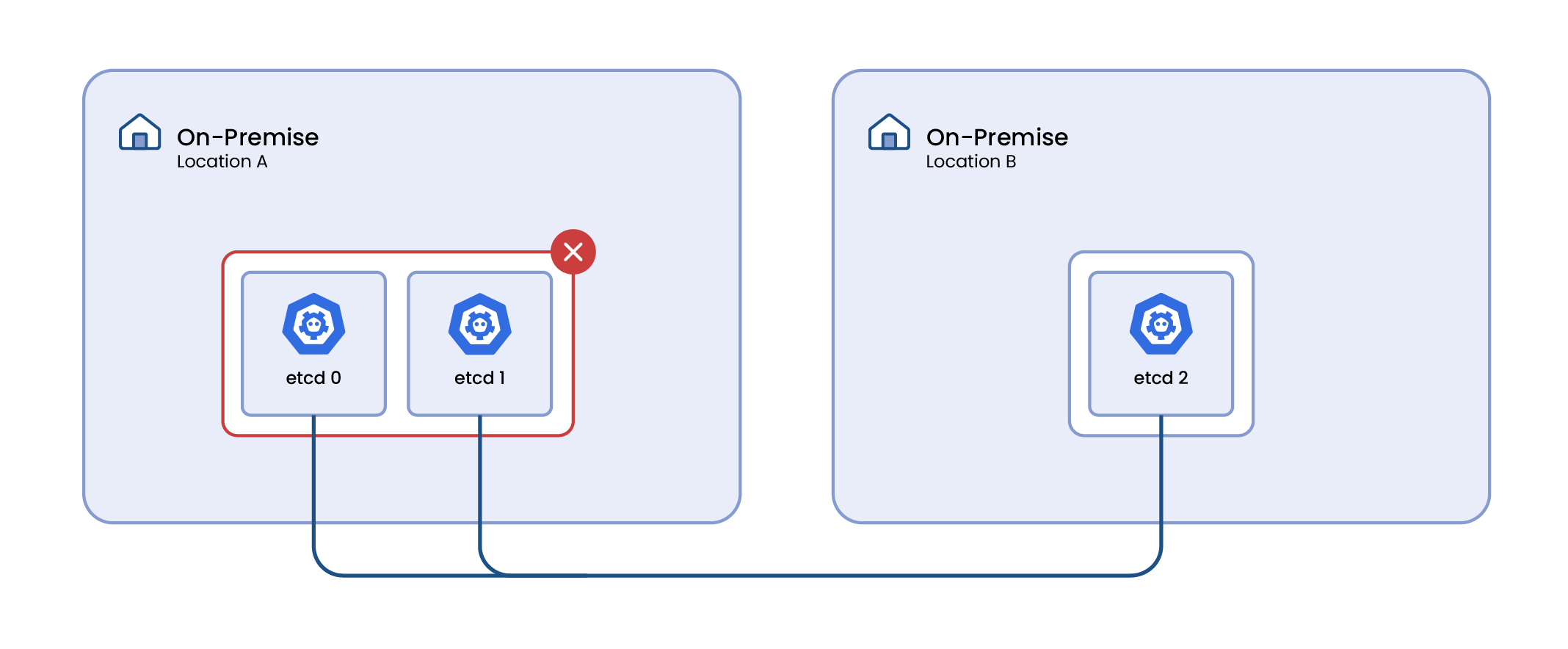
Increasing the number of etcd instances does not inherently mitigate this risk. The fundamental issue lies in the distribution of these instances across physical locations, not in their quantity. Even with a larger number of instances, if a majority is located in one zone and that zone fails, the cluster will still face downtime.
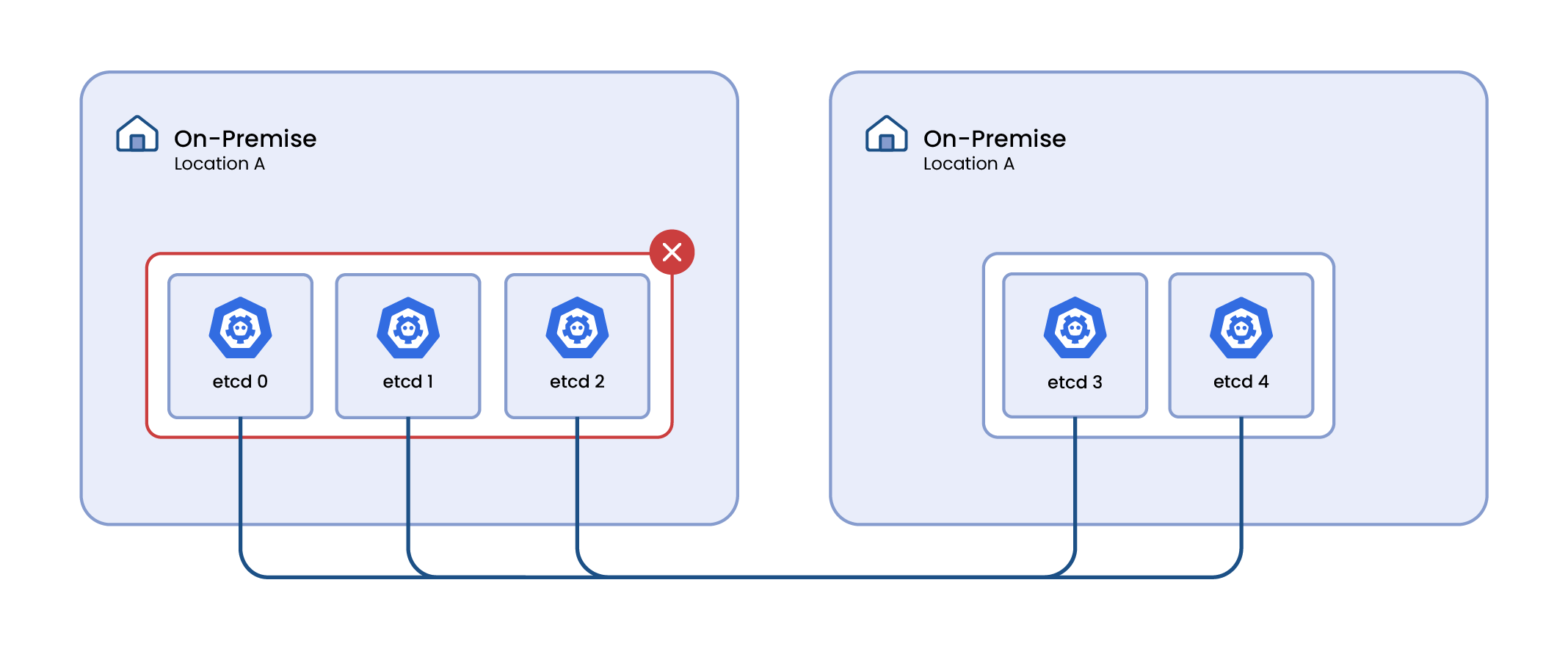
This scenario underlines the importance of not only the number of etcd instances but also their strategic distribution across multiple, ideally more than two, physical locations or zones to ensure fault tolerance and high availability.
This approach is vital to maintain the operational integrity of Kubernetes clusters, especially in environments where high availability and resilience are critical.
However, what could we do as an organization relying on an on-premises infrastructure which doesn't meet the etcd criteria of an odd number of availability zones?
Enter Kamaji: Empowering On-Premises Infrastructures with Hybrid Cloud Capabilities
To address these challenges and enable on-premises infrastructures to achieve high availability, a novel solution emerges – Kamaji.
By strategically leveraging the multi-zone capabilities offered by public cloud providers such as AWS, Azure, or GCP, Kamaji presents a viable solution to the fault tolerance challenges faced in a two-zone setup.
These cloud platforms typically provide multiple availability zones within each region. By distributing etcd as well as the entire Kubernetes Control Plane across these zones, it's possible to achieve a higher level of fault tolerance and resilience. In the event of a zone failure, the distributed nature of etcd instances ensures that a majority of them remain operational, thus maintaining the cluster's availability and preventing downtime.
In this paper, we’re not considering the case of synchronous replicas of etcd disks across the two zones. Even in that case, network timeouts and large recovery time can possibly lead to inconsistencies and data corruption of the etcd.
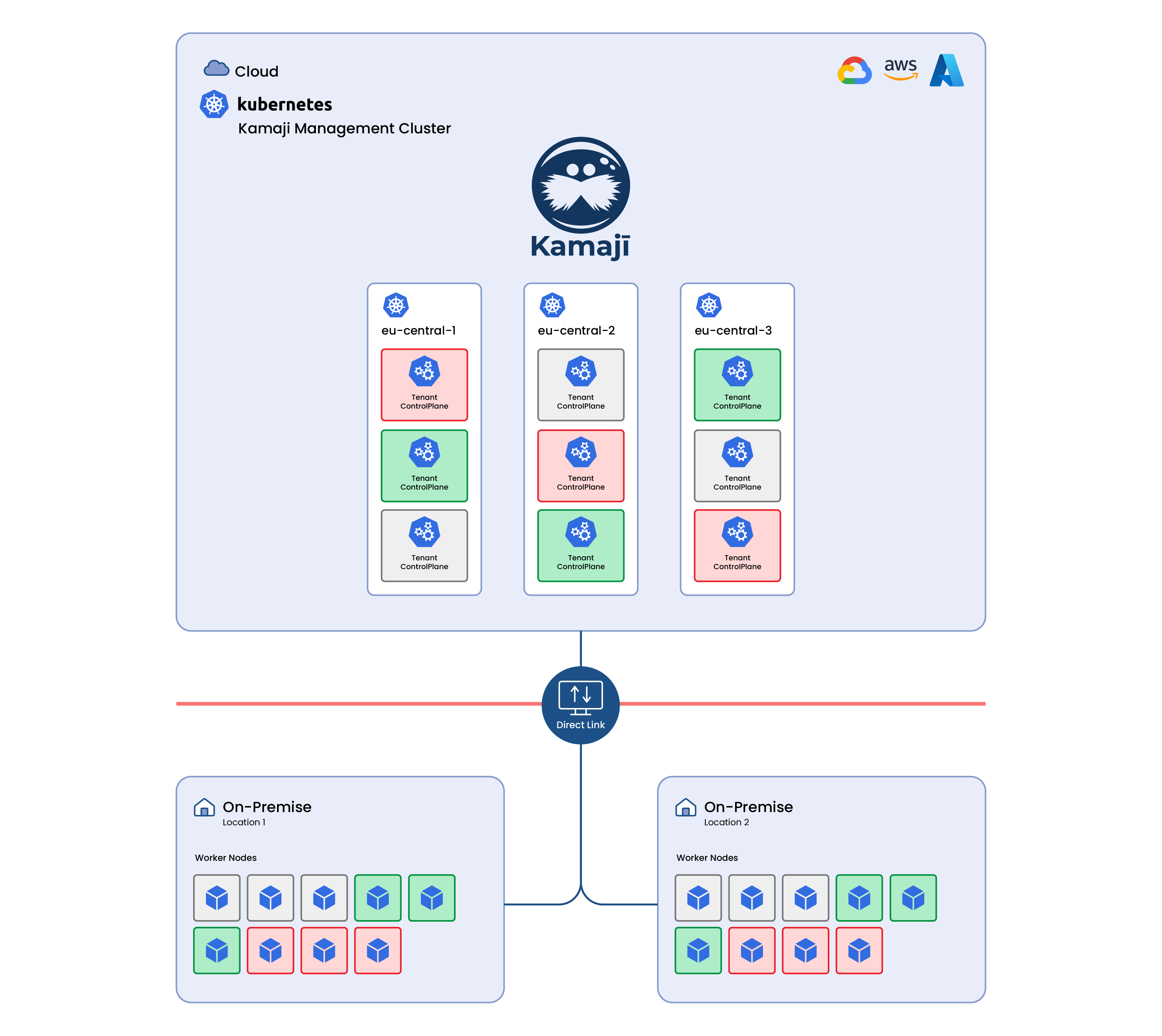
When worker nodes are located on-premises and the control plane, including etcd instances, is hosted in the cloud, the security and reliability of the connection between them become crucial. This setup requires a robust, reliable, and secure network connection.
For those organizations which need a Hybrid Cloud, a Cloud Direct Link is generally available according to the selected cloud provider: this component plays a crucial role.
A Direct Link is a dedicated, high-bandwidth network connection that provides a direct and private link between an organization's on-premises data centre or network and a specific cloud service provider's infrastructure. This type of connection is typically used to establish a reliable, low-latency, and secure communication channel between the organization's private network and the resources hosted in the cloud.
Furthermore, Kamaji offers seamless integration with Konnectivity, a networking solution designed to simplify and secure communication between cluster nodes placed across different networks. Acting as a proxy, it facilitates secure access to services within the cluster, addressing challenges related to load balancing, encryption, and external connectivity.
Along with Direct Link, Kamaji’s Konnectivity Server integration enhances Kubernetes networking by providing a unified and secure gateway for managing inbound and outbound traffic, streamlining connectivity management for distributed applications.
Key Benefits of Hybrid Control Planes
Konnectivity integration: By toggling the integration, Kamaji will provision the addon by hiding the whole complexity and ensuring a high availability Control Plane offloaded to the cloud.
Cluster API: manages your hybrid clusters powered by Cluster API, the declarative tool which allows managing a fleet of clusters; the CLASTIX team developed the Control Plane provider, allowing organizations to deploy worker nodes on-premises such as VMware Vsphere, OpenStack, Metal3, or KubeVirt, and getting the Control Plane externally managed on the Cloud
Flexibility: Kamaji facilitates the adoption of a hybrid cloud model, allowing organizations to combine on-premises resources with the scalability and flexibility of the cloud. This approach enables seamless workload migration, resource optimization, and efficient utilization of cloud services.
Reduced Operational Complexity: Managing a Kubernetes cluster spread across on-premises and cloud environments can be complex. Kamaji simplifies this process by centralizing the control plane in the cloud, reducing operational overhead and streamlining the overall management of the Kubernetes infrastructure.
Achieving true fault tolerance for the Control Plane: Kamaji allows organizations to offload the Kubernetes control plane to the cloud, where advanced cloud services provide a more resilient and redundant environment. This ensures that even in on-premises infrastructures with limited availability zones, the control plane remains highly available.
Network failure
Considering the fallacies of distributed computing, Hybrid Control Planes could be susceptible to network failures, leaving the worker nodes in a headless mode until a connection is established back with the Control Plane.
Also, in these scenarios, Kamaji helps address these events: thanks to its software-defined approach, it's possible to replicate the Datastore volumes across sites, following the best practices of the selected CSI and answering Disaster Recovery requirements and criteria.
In case of network failure, a copy of the Control Plane instances and related data can be spun up in a different location, keeping the resilience of the Kubernetes worker nodes infrastructure unaffected by the given failure.
Conclusion
In the ever-evolving landscape of container orchestration, addressing the challenges posed by limited availability zones in on-premises infrastructures is crucial. Kamaji emerges as a powerful solution thanks to its native integration with Cluster API, and the native Konnectivity support even for those organizations that haven’t a Cloud Direct Link, empowering organizations to bridge the gap between on-premises and the cloud.
By strategically placing the Kubernetes control plane in the cloud, Kamaji not only ensures the high availability of the etcd cluster but also opens the door to a hybrid cloud approach, unlocking new levels of flexibility, scalability, and operational efficiency for modern enterprises.